Tutorial: z-Axis detection of (simulated) glass beads#
Having tested the model on spots, we now want to assess the performance using a reference stack of glass beads provided by the Taute Lab
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
import sys
sys.path.append("..")
import ultralytics
import matplotlib.patches as patches
from matplotlib import colormaps as cmaps
import os
from tqdm import tqdm
import yaml
from importlib import reload # Python 3.4+
import pandas as pd
import image_generator as ig
from yundon_functions import *
pi = np.pi
from multiprocessing import Pool
from PIL import Image
from cv2 import resize
from itertools import repeat
from matplotlib.patches import Rectangle, Circle
# %matplotlib widget
import cv2
from ultralytics.utils import ops
from YOLOtrack11 import YOLOtrack11
from scipy.stats import binned_statistic
def plot_result(ax,img,objects, vmin=1.95e4, vmax=2.05e4):
if isinstance(img, PIL.Image.Image) or isinstance(img, np.ndarray):
pass
elif(type(img) == str):
img = PIL.Image.open(img)
ax.imshow(img,cmap="grey",vmin=vmin,vmax=vmax)
ax.axis("off")
for i,obj in objects.iterrows():
l,x,y,w,h = obj[:5]
rect = Rectangle((x-0.5*w,y-0.5*h),h,w, linewidth=1, edgecolor="yellow", facecolor='none')
tx,ty = rect.get_xy()
ax.add_patch(rect)
tx+=6
ty-=12
circle = Circle((x,y),1, facecolor="red",edgecolor="red")
ax.add_patch(circle)
if l == "Ripple":
ax.text(tx,ty,f"{obj["z"]*0.134:.3f}",fontsize="small",bbox=dict(facecolor='white', alpha=0.5,))
def plot_result_old(ax,img,cls,bboxes=repeat(None),z=None,kpts=None, conf=None,vmin=1.95e4,vmax=2.05e4):
is_conf = conf is not None
if not is_conf:
conf = np.zeros_like(cls)
if isinstance(img, PIL.Image.Image):
pass
elif(type(img) == str):
img = PIL.Image.open(img)
ax.imshow(img,cmap="grey",vmin=vmin,vmax=vmax)
ax.axis("off")
for bbox,z_value,kpt,c in zip(bboxes, z, kpts,conf):
if(bbox is not None):
x,y,w,h = bbox
rect = Rectangle((x-0.5*w,y-0.5*h),h,w, linewidth=1, edgecolor="yellow", facecolor='none')
tx,ty = rect.get_xy()
ax.add_patch(rect)
tx+=6
ty-=12
else:
tx,ty = kpt
ty-=40
tx-=50
circle = Circle(kpt,1, facecolor="red",edgecolor="red")
ax.add_patch(circle)
ax.text(tx,ty,f"z={z_value:.3f}" + (f", {c*100:.0f}%" if is_conf else ""),fontsize="small",bbox=dict(facecolor='white', alpha=0.5,))
return bboxes
def plot_gt(path,ax,imgsz=[512,512],vmin=1.95e4,vmax=2.05e4):
data=np.atleast_2d(np.loadtxt(path.replace("images", "labels").replace("jpg","txt").replace("tif","txt"))).T
# print(data)
if(len(data)==0):
return plot_result_old(ax,path, np.empty(0),np.empty((0,4)),np.empty(0),np.empty((0,0)),vmin=vmin,vmax=vmax)
cls = data[0]
bboxes = data[1:5].T*(imgsz*2)
z = data[5]
kpts = data[7:].T*imgsz
# print(bboxes)
return plot_result_old(ax,path, cls,bboxes,z,kpts, vmin=vmin,vmax=vmax)
ripple_params = {"label":"Ripple", "z":[0,1567], "i":1, "n":(20,30)}
parameter_list = [ripple_params]
reload(ig)
# Load the downsampled reference stack
downsampled_refstack = (np.load("../ripples_downsampled.npy"))-2e4 # shape (1568, 128, 128)
x0, y0 = 64.4, 63.7 # Center of the reference stack
image_size = 540,640 # Dimension
distance = 0 # Min distance between points
no_overlap = True
offset = 0 # Boundary padding
noise = [47,47] # This time, we use an absolute noise, since the SNR cannot be defined for the whole image, it is dependent on the z position
objects = ig.getRandom(parameter_list, image_size, distance=distance,distance_consider_object_size=no_overlap, offset=offset)
plt.close("all")
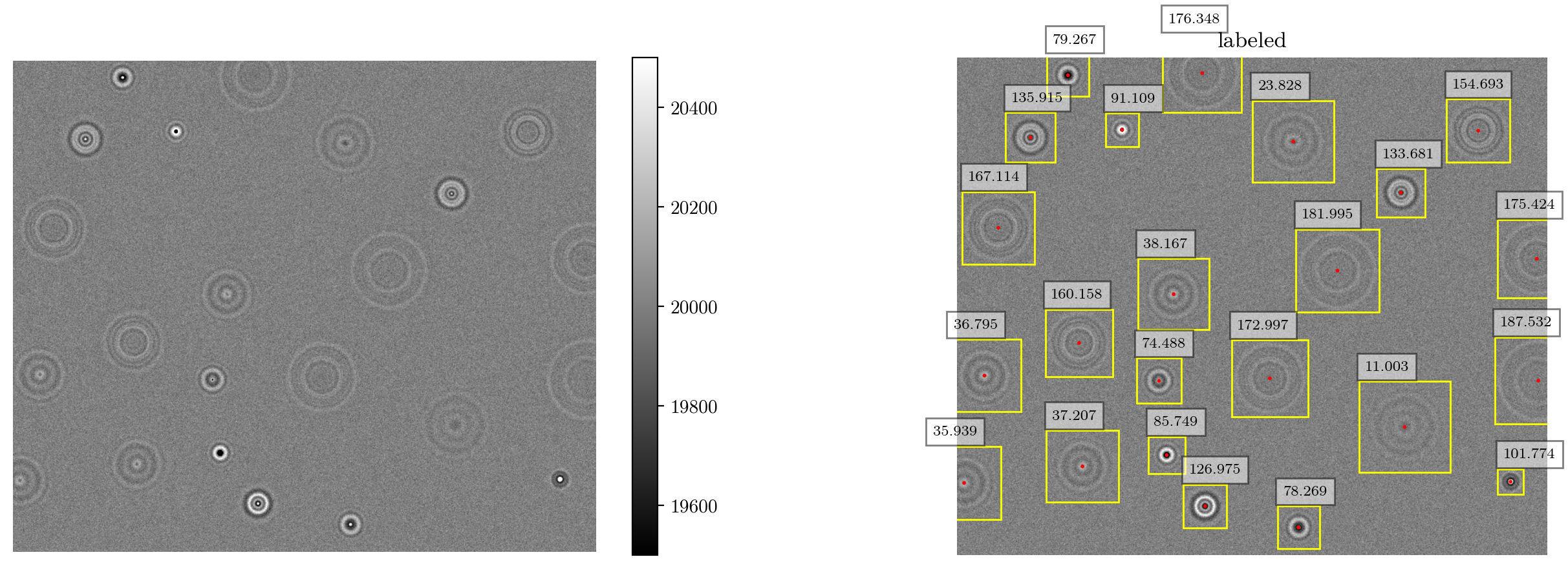
plt.figure(figsize=(16,5))
image,_ = ig.generateImage(objects, image_size, refstack=downsampled_refstack, refstack_center=(y0,x0),noise=noise, background=2e4)
ax = plt.subplot(1,2,1)
ax.axis("off")
plt.imshow(image, cmap="grey",vmin=1.95e4,vmax=2.05e4)
plt.colorbar()
ax = plt.subplot(1,2,2)
plt.title("labeled")
plot_result(ax,image,objects)
ax.axis("off")
# plt.tight_layout()
plt.show()
Now, let’s generate some training data!
subdir = '../datasets/Dataset_ripples/'
nimages = [25000,10000,1000]
folders = ["train_no_overlap","val_no_overlap_slow", "val_no_overlap_fast"]
import time
reload(ig)
if not os.path.exists(subdir):
os.mkdir(subdir)
l_dir = subdir + 'labels'
i_dir = subdir + 'images'
if not os.path.exists(i_dir):
os.mkdir(i_dir)
if not os.path.exists(l_dir):
os.mkdir(l_dir)
for i, prefix in enumerate(folders):
image_dir = i_dir + '/' + prefix + '/'
if not os.path.exists(image_dir):
os.mkdir(image_dir)
label_dir = l_dir + '/' + prefix + '/'
if not os.path.exists(label_dir):
os.mkdir(label_dir)
for i, prefix in enumerate(folders):
vectorized_index = np.vectorize(lambda labels,item: labels.index(item))
rngs = []
def init():
# Initialize the random number generator for each process
global rng #the rng variable is global so that it can be used in the call function
rng = np.random.default_rng()
time.sleep(rng.uniform(0,2))
def call(j):
labelname = l_dir + '/' + prefix + '/' + 'image_{:05d}.txt'.format(j,2)
fname = i_dir + '/' + prefix + '/' + 'image_{:05d}.tif'.format(j,2)
for _ in range(20):
try:
objects = ig.getRandom(parameter_list, image_size, rng=rng, distance=distance, distance_consider_object_size=no_overlap, offset=offset)
break
except RuntimeError:
continue
else:
raise RuntimeError("couldn't find object placement after 10 tries")
if(len(objects) == 0):
f = open(labelname, "w")
f.write("\n")
f.close()
return
image, info_dict = ig.generateImage(objects, image_size , noise=noise, rng=rng, refstack=downsampled_refstack, refstack_center=(y0,x0))
image = (image).astype(np.uint16) #cast image to 16 bit uint for tiff
image = Image.fromarray(image).save(fname, quality=100)
objects[["x","w"]] /= image_size[1] # scale x and w to [0,1]
objects[["y","h"]] /= image_size[0] # scale y and h to [0,1]
objects["z"] = (objects["z"]-761)*0.134
# turn label into int:
objects["label"]=pd.factorize(objects["label"])[0]
# add keypoint coordinates
objects[["kpt_x", "kpt_y"]] = objects[["x", "y"]]
np.savetxt(labelname, objects.values, fmt='%g')# label x y w h z i x y
with Pool(initializer=init) as pool:
for _ in tqdm(pool.imap_unordered(call,range(nimages[i])),total=nimages[i], desc=prefix):
pass
global rng
rng = np.random.default_rng()
val_no_overlap: 100%|██████████| 1000/1000 [00:04<00:00, 208.00it/s]
generate the corresponding yaml files
subdir = '../datasets/Dataset_ripples/'
file_path = '../datasets/ripples_fast.yaml'
dict = {}
dict["train"]=os.getcwd() + '/' + subdir + "images/" + "train"
dict["val"]=os.getcwd() + '/' + subdir + "images/" + "val_fast"
dict["kpt_shape"] = [1,2]
dict["num_extra_parameters"] = 2
dict['nc'] = 1
dict['names'] = ["Spot"]
with open(file_path, 'w') as file:
yaml.dump(dict, file, default_flow_style=True)
file_path = '../datasets/ripples_slow.yaml'
dict = {}
dict["train"]=os.getcwd() + '/' + subdir + "images/" + "train"
dict["val"]=os.getcwd() + '/' + subdir + "images/" + "val_slow"
dict["kpt_shape"] = [1,2]
dict["num_extra_parameters"] = 2
dict['nc'] = 1
dict['names'] = ["Spot"]
with open(file_path, 'w') as file:
yaml.dump(dict, file, default_flow_style=True)
file_path = '../datasets/ripples_no_overlap_fast.yaml'
dict = {}
dict["train"]=os.getcwd() + '/' + subdir + "images/" + "train_no_overlap"
dict["val"]=os.getcwd() + '/' + subdir + "images/" + "val_no_overlap_fast"
dict["kpt_shape"] = [1,2]
dict["num_extra_parameters"] = 2
dict['nc'] = 1
dict['names'] = ["Spot"]
with open(file_path, 'w') as file:
yaml.dump(dict, file, default_flow_style=True)
file_path = '../datasets/ripples_no_overlap_slow.yaml'
dict = {}
dict["train"]=os.getcwd() + '/' + subdir + "images/" + "train_no_overlap"
dict["val"]=os.getcwd() + '/' + subdir + "images/" + "val_no_overlap_slow"
dict["kpt_shape"] = [1,2]
dict["num_extra_parameters"] = 2
dict['nc'] = 1
dict['names'] = ["Spot"]
with open(file_path, 'w') as file:
yaml.dump(dict, file, default_flow_style=True)
from YOLOtrack11 import YOLOtrack11
model = YOLOtrack11("yolo11n-zaxis.yaml")
results = model.train(data="datasets/ripples_no_overlap_fast.yaml", imgsz=(640,540), epochs=50)#, z=5,freeze=22,box=0,cls=0,dfl=0,pose=0)
model.save("yolo11n_ripples_custom_level.pt")
Show code cell output
New https://pypi.org/project/ultralytics/8.3.155 available 😃 Update with 'pip install -U ultralytics'
Ultralytics 8.3.79 🚀 Python-3.12.6 torch-2.5.1+cu124 CUDA:0 (NVIDIA GeForce RTX 4090, 24202MiB)
trainer: task=zaxis, mode=train, model=yolo11n-zaxis.yaml, data=datasets/ripples_no_overlap_fast.yaml, epochs=10, time=None, patience=100, batch=16, imgsz=(640, 540), save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=train243, exist_ok=False, pretrained=True, optimizer=SGD, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=False, fraction=1.0, profile=False, freeze=None, multi_scale=False, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=False, source=None, vid_stride=1, stream_buffer=False, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, embed=None, show=False, save_frames=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, show_boxes=True, line_width=None, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=True, opset=None, workspace=4, nms=False, lr0=0.005, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=5000.0, kobj=1.0, z=0.05, label_smoothing=0.0, nbs=64, hsv_h=0.0, hsv_s=0.0, hsv_v=0.0, degrees=0.0, translate=0.0, scale=0.0, shear=0.0, perspective=0.0, flipud=0.5, fliplr=0.5, bgr=0.0, mosaic=0.0, mixup=0.0, copy_paste=0.0, copy_paste_mode=flip, auto_augment=None, erasing=0.0, crop_fraction=1.0, cfg=None, tracker=botsort.yaml, background=20000, level=20000, window=500, save_dir=/home/jupyter-till/git/ultralytics/runs/zaxis/train243
from n params module arguments
0 -1 1 176 ultralytics.nn.modules.conv.Conv [1, 16, 3, 2]
1 -1 1 4672 ultralytics.nn.modules.conv.Conv [16, 32, 3, 2]
2 -1 1 6640 ultralytics.nn.modules.block.C3k2 [32, 64, 1, False, 0.25]
3 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
4 -1 1 26080 ultralytics.nn.modules.block.C3k2 [64, 128, 1, False, 0.25]
5 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
6 -1 1 87040 ultralytics.nn.modules.block.C3k2 [128, 128, 1, True]
7 -1 1 295424 ultralytics.nn.modules.conv.Conv [128, 256, 3, 2]
8 -1 1 346112 ultralytics.nn.modules.block.C3k2 [256, 256, 1, True]
9 -1 1 164608 ultralytics.nn.modules.block.SPPF [256, 256, 5]
10 -1 1 249728 ultralytics.nn.modules.block.C2PSA [256, 256, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
13 -1 1 111296 ultralytics.nn.modules.block.C3k2 [384, 128, 1, False]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 1 32096 ultralytics.nn.modules.block.C3k2 [256, 64, 1, False]
17 -1 1 36992 ultralytics.nn.modules.conv.Conv [64, 64, 3, 2]
18 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
19 -1 1 86720 ultralytics.nn.modules.block.C3k2 [192, 128, 1, False]
20 -1 1 147712 ultralytics.nn.modules.conv.Conv [128, 128, 3, 2]
21 [-1, 10] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 1 378880 ultralytics.nn.modules.block.C3k2 [384, 256, 1, True]
23 [16, 19, 22] 1 574303 YOLOtrack11.model.ZAxis [1, 2, [1, 2], [64, 128, 256]]
YOLO11n-zaxis summary: 211 layers, 2,733,183 parameters, 2,733,167 gradients, 6.9 GFLOPs
Freezing layer 'model.23.dfl.conv.weight'
WARNING ⚠️ updating to 'imgsz=640'. 'train' and 'val' imgsz must be an integer, while 'predict' and 'export' imgsz may be a [h, w] list or an integer, i.e. 'yolo export imgsz=640,480' or 'yolo export imgsz=640'
train: Scanning /home/jupyter-till/git/YOLOTrack11/datasets/Dataset_ripples/labels/train_no_overlap.cache... 25000 images, 0 backgrounds, 0 corrupt: 100%|██████████| 25000/25000 [00:00<?, ?it/s]
val: Scanning /home/jupyter-till/git/YOLOTrack11/datasets/Dataset_ripples/labels/val_no_overlap_fast.cache... 1000 images, 0 backgrounds, 0 corrupt: 100%|██████████| 1000/1000 [00:00<?, ?it/s]
WARNING ⚠️ 'label_smoothing' is deprecated and will be removed in in the future.
optimizer: SGD(lr=0.005, momentum=0.937) with parameter groups 93 weight(decay=0.0), 106 weight(decay=0.0005), 105 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to /home/jupyter-till/git/ultralytics/runs/zaxis/train243
Starting training for 10 epochs...
Closing dataloader mosaic
Epoch GPU_mem box_loss cls_loss dfl_loss zaxis_loss pose_loss kobj_loss Instances Size
1/10 4.49G 3.64 3.637 4.222 283.4 90.36 0 388 640: 17%|█▋ | 266/1563 [00:14<01:12, 17.98it/s]
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[4], line 3
1 from YOLOtrack11 import YOLOtrack11
2 model = YOLOtrack11("yolo11n-zaxis.yaml")
----> 3 results = model.train(data="datasets/ripples_no_overlap_fast.yaml", imgsz=(640,540), epochs=10)#, z=5,freeze=22,box=0,cls=0,dfl=0,pose=0)
4 model.save("yolo11n_ripples_custom_level.pt")
File ~/.local/lib/python3.12/site-packages/ultralytics/engine/model.py:810, in Model.train(self, trainer, **kwargs)
807 self.model = self.trainer.model
809 self.trainer.hub_session = self.session # attach optional HUB session
--> 810 self.trainer.train()
811 # Update model and cfg after training
812 if RANK in {-1, 0}:
File ~/.local/lib/python3.12/site-packages/ultralytics/engine/trainer.py:208, in BaseTrainer.train(self)
205 ddp_cleanup(self, str(file))
207 else:
--> 208 self._do_train(world_size)
File ~/.local/lib/python3.12/site-packages/ultralytics/engine/trainer.py:393, in BaseTrainer._do_train(self, world_size)
391 # Optimize - https://pytorch.org/docs/master/notes/amp_examples.html
392 if ni - last_opt_step >= self.accumulate:
--> 393 self.optimizer_step()
394 last_opt_step = ni
396 # Timed stopping
File ~/.local/lib/python3.12/site-packages/ultralytics/engine/trainer.py:599, in BaseTrainer.optimizer_step(self)
597 self.optimizer.zero_grad()
598 if self.ema:
--> 599 self.ema.update(self.model)
File ~/.local/lib/python3.12/site-packages/ultralytics/utils/torch_utils.py:544, in ModelEMA.update(self, model)
542 if v.dtype.is_floating_point: # true for FP16 and FP32
543 v *= d
--> 544 v += (1 - d) * msd[k].detach()
KeyboardInterrupt:
Testing the model on images generated with the Taute Lab refstack#
model = YOLOtrack11("yolo11n_ripples_no_overlap.pt")
imgsz=640,540
dataset_path = "../datasets/Dataset_ripples/images/val_no_overlap_slow"
test_images = os.listdir(dataset_path)
random_image = lambda: dataset_path+"/"+test_images[np.random.randint(0,len(test_images))]
Show code cell source
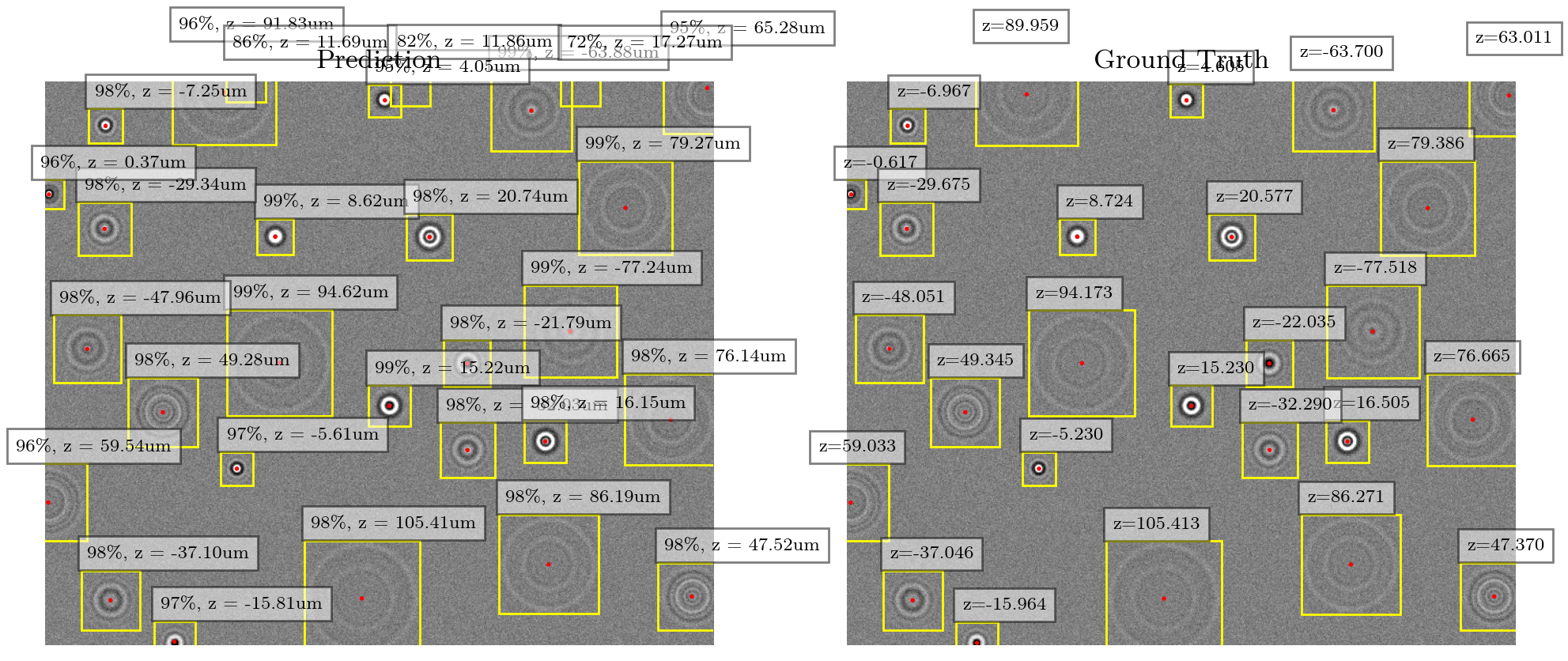
if not plt.get_fignums() : plt.figure(figsize=(12,5))
else: plt.clf()
image = random_image()
img = np.array(PIL.Image.open(image))
results = model.predict(np.array(img), conf = 0.7)
res = results[0].zaxis.data.cpu().numpy()
plt.subplot(1,2,1)
plt.title("Prediction")
# kpt = res[:,8:]
# bbox = res[:,:4]
# z = res[:,6]
# plot_result(plt.gca(),img,res[:,4],ops.xyxy2xywh(bbox),z,kpt,conf=res[:,4], vmin=1.95e4, vmax=2.05e4)
results[0].plot(plt.gca(),vmin=1.95e4, vmax=2.05e4)
plt.axis("off")
plt.subplot(1,2,2)
plt.title("Ground Truth")
plot_gt(image,plt.gca(),imgsz, vmin=1.95e4, vmax=2.05e4)
plt.show()
0: 544x640 29 Spots, 6.0ms
Speed: 6.1ms preprocess, 6.0ms inference, 11.3ms postprocess per image at shape (1, 3, 544, 640)
Let’s evaluate the model on the “slow” validation set, containing 10000 images:
model_paths = "yolo11n_ripples_no_overlap.pt", "yolo11n_ripples.pt"
dataset_paths = "../datasets/ripples_no_overlap_slow.yaml", "../datasets/ripples_slow.yaml"
results = []
for model_path, dataset_path in zip(model_paths, dataset_paths):
model = YOLOtrack11(model_path)
res = model.val(data=dataset_path, workers=0, background=2e4, conf=0.8)
results.append(res)
Ultralytics 8.3.79 🚀 Python-3.12.6 torch-2.5.1+cu124 CUDA:0 (NVIDIA GeForce RTX 4090, 24202MiB)
YOLO11n-zaxis summary (fused): 118 layers, 2,725,303 parameters, 0 gradients, 6.7 GFLOPs
image size: 640
val: Scanning /home/jupyter-till/git/YOLOTrack11/datasets/Dataset_ripples/labels/val_no_overlap_slow.cache... 10000 images, 0 backgrounds, 0 corrupt: 100%|██████████| 10000/10000 [00:00<?, ?it/s]
Class Images Instances Box(P R mAP50 mAP50-95) z rms. xy rms.: 100%|██████████| 625/625 [00:27<00:00, 22.94it/s]
all 10000 235792 1 1 0.995 0.995 0.424 0.229
Speed: 0.0ms preprocess, 0.5ms inference, 0.0ms loss, 0.2ms postprocess per image
Ultralytics 8.3.79 🚀 Python-3.12.6 torch-2.5.1+cu124 CUDA:0 (NVIDIA GeForce RTX 4090, 24202MiB)
YOLO11n-zaxis summary (fused): 118 layers, 2,725,303 parameters, 0 gradients, 6.7 GFLOPs
image size: 640
val: Scanning /home/jupyter-till/git/YOLOTrack11/datasets/Dataset_ripples/labels/val_slow.cache... 10000 images, 0 backgrounds, 0 corrupt: 100%|██████████| 10000/10000 [00:00<?, ?it/s]
Class Images Instances Box(P R mAP50 mAP50-95) z rms. xy rms.: 100%|██████████| 625/625 [00:29<00:00, 21.23it/s]
all 10000 599713 1 0.987 0.993 0.991 1.19 0.492
Speed: 0.0ms preprocess, 0.5ms inference, 0.0ms loss, 0.2ms postprocess per image
Show code cell source
plt.figure(figsize=(12,3))
plt.subplot(121)
crlb = np.load("crlb_results.npz")
bins= 200
z = np.linspace(-102,108,bins)
bins_=np.linspace(-102,108,bins+1)
crlb_xy = np.interp(z, crlb["z_space"], crlb["std_xy"])
k=10
crlb_z = np.interp(z, crlb["z_space"][k//2:-k//2:k], np.convolve(crlb["std_z"], np.ones(k)/k, mode='same')[k//2:-k//2:k])
y, x,_ = binned_statistic(results[1].xyz_pairs[:,0,2], results[1].xy_distances**2, bins=bins_, statistic=np.nanmean)
plt.step(z,np.sqrt(y), where="mid")
y, x,_ = binned_statistic(results[0].xyz_pairs[:,0,2], results[0].xy_distances**2, bins=bins_, statistic=np.nanmean)
plt.step(z,np.sqrt(y), where="mid")
# plt.hist(results[0].xyz_pairs[:,0,2], bins=bins_)
plt.plot(z, crlb_xy, "--", c="k", lw=0.9)
plt.yscale("log")
plt.xlabel("z / µm")
plt.ylabel("xy rms. / px")
plt.subplot(122)
y, x,_ = binned_statistic(results[1].xyz_pairs[:,0,2], np.subtract(*results[1].xyz_pairs[:,:,2].T)**2, bins=bins_, statistic=np.nanmean)
plt.step(z,np.sqrt(y), label="with overlap", where="mid")
y, x,_ = binned_statistic(results[0].xyz_pairs[:,0,2], np.subtract(*results[0].xyz_pairs[:,:,2].T)**2, bins=bins_, statistic=np.nanmean)
plt.step(z,np.sqrt(y), label="no overlap", where="mid")
k=10
plt.plot(z,crlb_z, "--", c="k", lw=0.9, label="CR lower bound")
plt.yscale("log")
plt.xlabel("z / µm")
plt.ylabel("z rms. / µm")
plt.legend()
# plt.ylim(0,7.5)
plt.tight_layout()
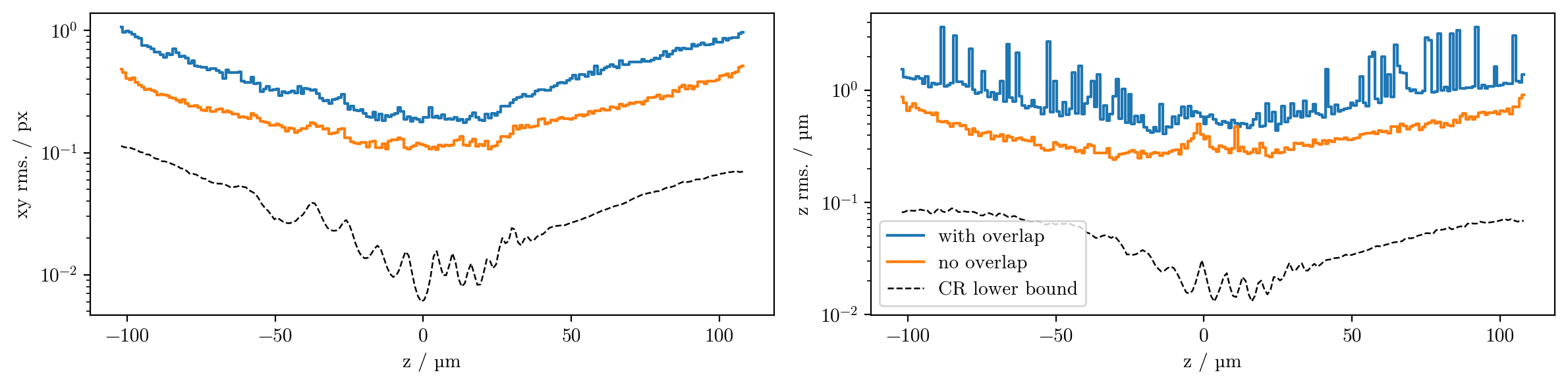
It seems strange that here, the CRLB is 1 order of magnitude below the model’s rms. We’re in much better noise conditions compared to the spot images, so we are in the plateaued region (see previous chapter), where noise is no longer the limiting factor
To see if there are any systematic errors, let’s look at the bias in x,y,z:
Show code cell source
bins= 200
z = np.linspace(-102,108,bins)
bins_=np.linspace(-102,108,bins+1)
plt.figure(figsize=(12,3))
plt.subplot(121)
z = np.linspace(-102,108,bins)
y, x,_ = binned_statistic(results[1].xyz_pairs[:,0,2], np.subtract(*results[1].xyz_pairs[:,:,0].T), bins=bins_, statistic=np.nanmean)
plt.step(z,y, where="mid")
y, x,_ = binned_statistic(results[0].xyz_pairs[:,0,2], np.subtract(*results[0].xyz_pairs[:,:,0].T), bins=bins_, statistic=np.nanmean)
plt.step(z,y, where="mid")
plt.xlabel("z / µm")
plt.ylabel("x bias / px")
plt.subplot(122)
y, x,_ = binned_statistic(results[0].xyz_pairs[:,0,2], np.subtract(*results[0].xyz_pairs[:,:,1].T), bins=bins_, statistic=np.nanmean)
plt.step(z,y, where="mid", label="with overlap")
y, x,_ = binned_statistic(results[1].xyz_pairs[:,0,2], np.subtract(*results[1].xyz_pairs[:,:,1].T), bins=bins_, statistic=np.nanmean)
plt.step(z,y, where="mid", label="without overlap")
# plt.hist(results[0].xyz_pairs[:,0,2], bins=bins_, statistic=np.nanmean)
plt.xlabel("z / µm")
plt.ylabel("y bias / px")
plt.figure(figsize=(5.5,3))
y, x,_ = binned_statistic(results[1].xyz_pairs[:,0,2], np.subtract(*results[1].xyz_pairs[:,:,2].T), bins=bins_, statistic=np.nanmean)
plt.step(z,y, label="with overlap", where="mid")
y, x,_ = binned_statistic(results[0].xyz_pairs[:,0,2], np.subtract(*results[0].xyz_pairs[:,:,2].T), bins=bins_, statistic=np.nanmean)
plt.step(z,y, label="no overlap", where="mid")
plt.xlabel("z / µm")
plt.ylabel("z bias / µm")
plt.legend()
plt.ylim(-0.4,0.4)
plt.tight_layout()
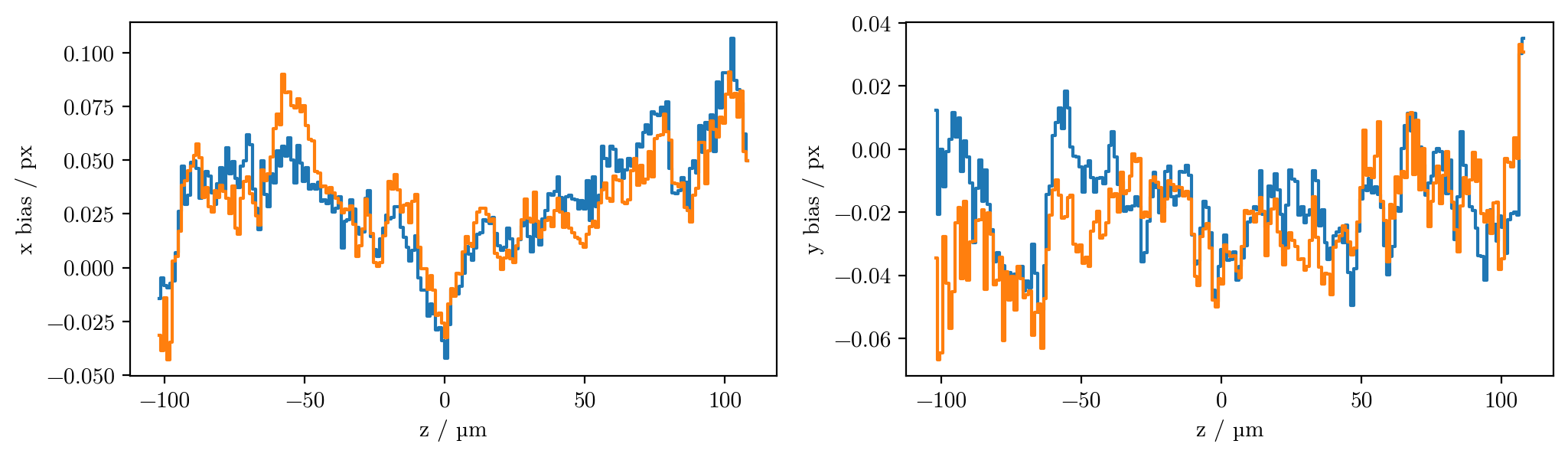
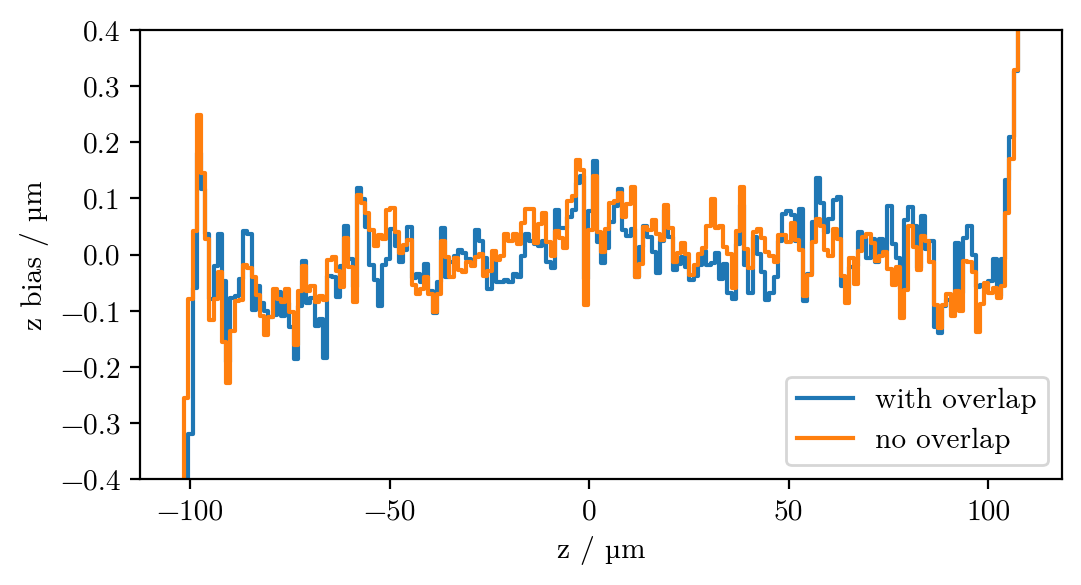
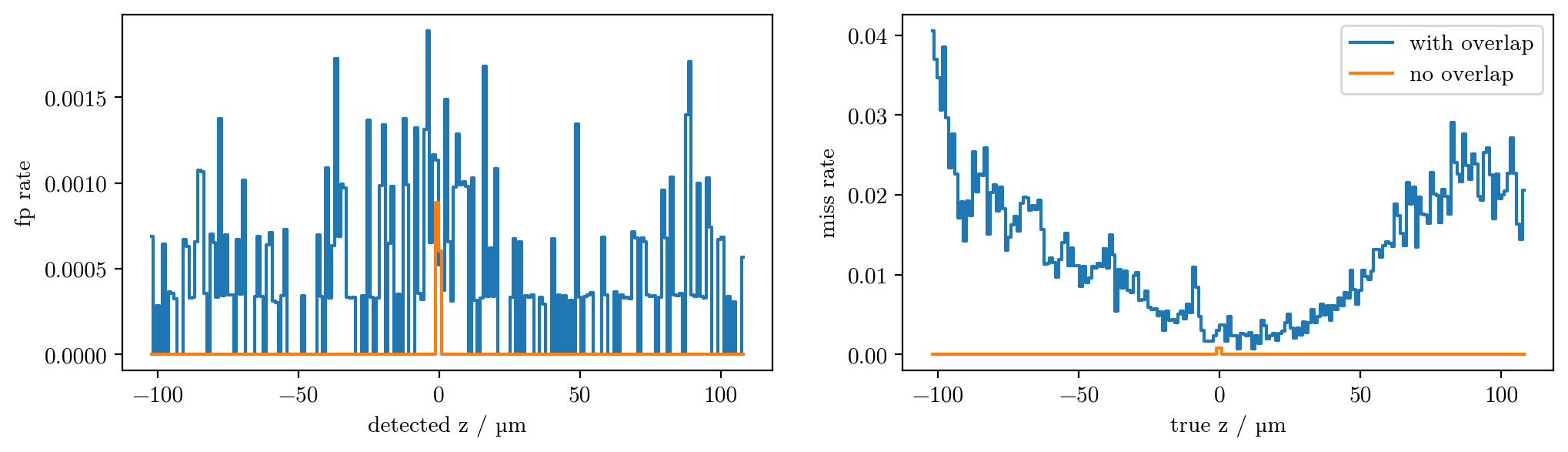
Why do we see this pattern in the x bias?
Show code cell source
bins= 200
z = np.linspace(-102,108,bins)
bins_=np.linspace(-102,108,bins+1)
plt.figure(figsize=(12,3))
plt.subplot(121)
y, x,_ = binned_statistic(results[1].xyz_pairs[:,1,2], results[1].fp, bins=bins_)
plt.step(z,y, where="mid", label="with overlap")
y, x,_ = binned_statistic(results[0].xyz_pairs[:,1,2], results[0].fp, bins=bins_)
plt.step(z,y, where="mid", label="no overlap")
plt.xlabel("detected z / µm")
plt.ylabel("fp rate")
plt.subplot(122)
y, x,_ = binned_statistic(results[1].xyz_pairs[:,0,2], results[1].fn, bins=bins_)
plt.step(z,y, where="mid", label="with overlap")
y, x,_ = binned_statistic(results[0].xyz_pairs[:,0,2], results[0].fn, bins=bins_)
plt.step(z,y, where="mid", label="no overlap")
plt.xlabel("true z / µm")
plt.ylabel("miss rate")
plt.legend()
<matplotlib.legend.Legend at 0x785ff97a48c0>
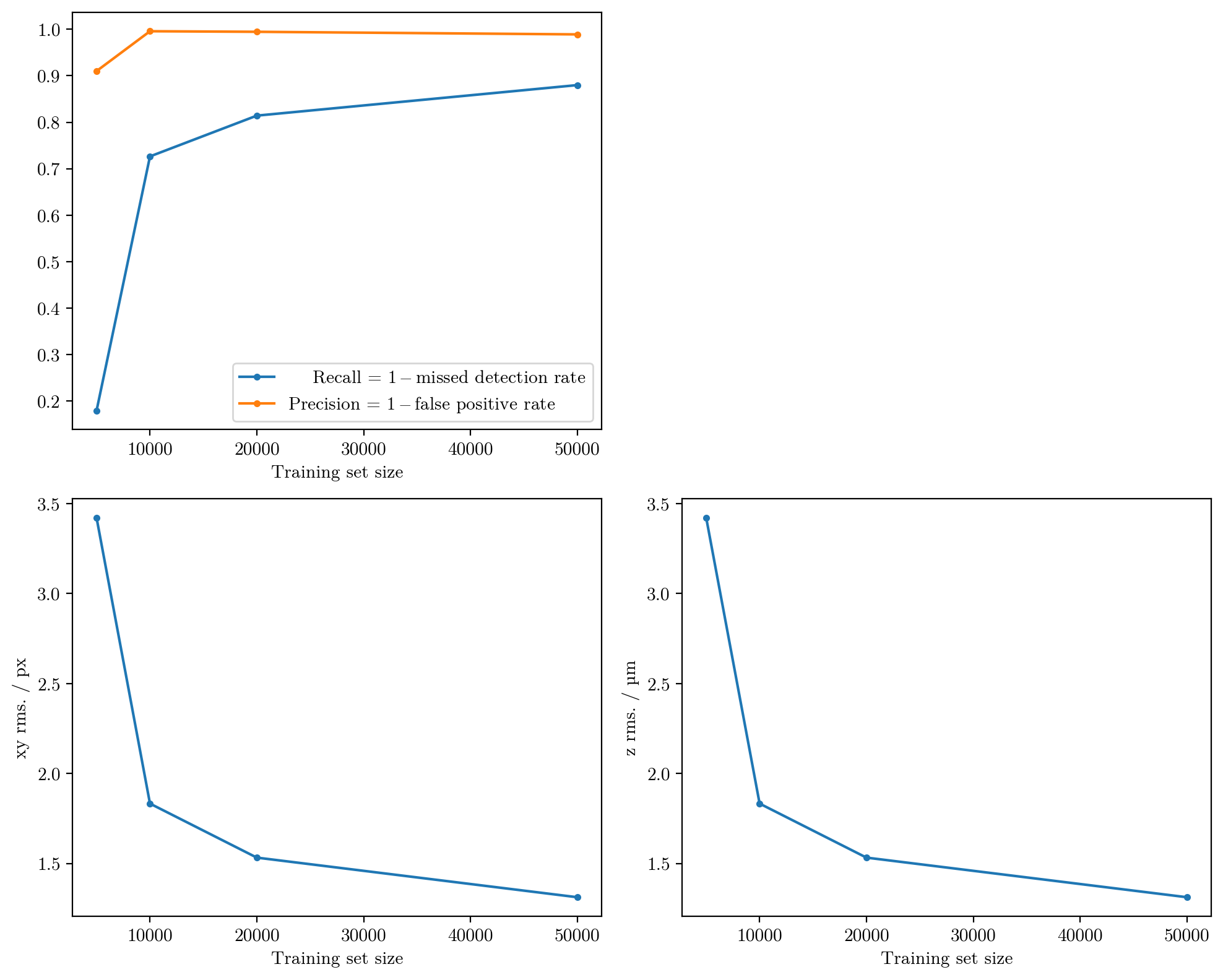
How does the performance vary with the training set size?#
Show code cell content
num = 5000,10000,20000,50000
model_idx = 163,159,161,162,122
results = []
for i,n in zip(model_idx,num):
model = YOLOtrack11(f"../../ultralytics/runs/pose/train{i}/weights/last.pt")
results.append(model.val(save=False, data=f'../datasets/snr10-13.yaml', workers=0, conf=0.8))
Ultralytics 8.3.79 🚀 Python-3.12.6 torch-2.5.1+cu124 CUDA:0 (NVIDIA GeForce RTX 4090, 24202MiB)
YOLO11n-zaxis summary (fused): 118 layers, 2,725,303 parameters, 0 gradients, 6.7 GFLOPs
val: Scanning /home/jupyter-till/git/YOLOTrack11/datasets/Dataset_subpixel/labels/val_snr10-13.cache... 10000 images, 0 backgrounds, 0 corrupt: 100%|██████████| 10000/10000 [00:00<?, ?it/s]
Class Images Instances Box(P R mAP50 mAP50-95) z rms. xy rms.: 100%|██████████| 625/625 [00:24<00:00, 25.46it/s]
all 10000 603115 0.91 0.179 0.544 0.352 9.53 4.09
Speed: 0.0ms preprocess, 0.5ms inference, 0.0ms loss, 0.2ms postprocess per image
Ultralytics 8.3.79 🚀 Python-3.12.6 torch-2.5.1+cu124 CUDA:0 (NVIDIA GeForce RTX 4090, 24202MiB)
YOLO11n-zaxis summary (fused): 118 layers, 2,725,303 parameters, 0 gradients, 6.7 GFLOPs
val: Scanning /home/jupyter-till/git/YOLOTrack11/datasets/Dataset_subpixel/labels/val_snr10-13.cache... 10000 images, 0 backgrounds, 0 corrupt: 100%|██████████| 10000/10000 [00:00<?, ?it/s]
Class Images Instances Box(P R mAP50 mAP50-95) z rms. xy rms.: 100%|██████████| 625/625 [00:20<00:00, 30.36it/s]
all 10000 603115 0.996 0.726 0.862 0.773 4.31 2.01
Speed: 0.0ms preprocess, 0.5ms inference, 0.0ms loss, 0.2ms postprocess per image
Ultralytics 8.3.79 🚀 Python-3.12.6 torch-2.5.1+cu124 CUDA:0 (NVIDIA GeForce RTX 4090, 24202MiB)
YOLO11n-zaxis summary (fused): 118 layers, 2,725,303 parameters, 0 gradients, 6.7 GFLOPs
val: Scanning /home/jupyter-till/git/YOLOTrack11/datasets/Dataset_subpixel/labels/val_snr10-13.cache... 10000 images, 0 backgrounds, 0 corrupt: 100%|██████████| 10000/10000 [00:00<?, ?it/s]
Class Images Instances Box(P R mAP50 mAP50-95) z rms. xy rms.: 100%|██████████| 625/625 [00:20<00:00, 30.89it/s]
all 10000 603115 0.995 0.814 0.906 0.846 3.07 1.68
Speed: 0.0ms preprocess, 0.5ms inference, 0.0ms loss, 0.2ms postprocess per image
Ultralytics 8.3.79 🚀 Python-3.12.6 torch-2.5.1+cu124 CUDA:0 (NVIDIA GeForce RTX 4090, 24202MiB)
YOLO11n-zaxis summary (fused): 118 layers, 2,725,303 parameters, 0 gradients, 6.7 GFLOPs
val: Scanning /home/jupyter-till/git/YOLOTrack11/datasets/Dataset_subpixel/labels/val_snr10-13.cache... 10000 images, 0 backgrounds, 0 corrupt: 100%|██████████| 10000/10000 [00:00<?, ?it/s]
Class Images Instances Box(P R mAP50 mAP50-95) z rms. xy rms.: 100%|██████████| 625/625 [00:19<00:00, 31.29it/s]
all 10000 603115 0.989 0.88 0.938 0.903 4.21 1.44
Speed: 0.0ms preprocess, 0.5ms inference, 0.0ms loss, 0.2ms postprocess per image
Show code cell source
plt.figure(figsize=(10,8))
plt.subplot(2,2,1)
plt.xlabel("Training set size")
plt.plot(num, [res.box.r for res in results], ".-",label=" Recall = $1 -$missed detection rate")
plt.plot(num, [res.box.p for res in results], ".-",label="Precision = $1 -$false positive rate")
plt.legend()
plt.subplot(2,2,3)
#plt.axvline(45,0,1,ls="dashed", lw=0.9, label="training lower noise bound")
#plt.axvline(50,0,1,ls="dashed", lw=0.9, label="training upper noise bound")
# plt.axvline(47,0,1,ls="dashed", lw=0.9, label="yundon's noise level")
plt.plot(num, [res.xy_rms[6] for res in results], ".-",)
plt.xlabel("Training set size")
plt.ylabel("xy rms. / px")
plt.subplot(2,2,4)
#plt.axvline(45,0,1,ls="dashed", lw=0.9, label="training lower noise bound")
#plt.axvline(50,0,1,ls="dashed", lw=0.9, label="training upper noise bound")
# plt.axvline(47,0,1,ls="dashed", lw=0.9, label="yundon's noise level")
plt.plot(num, [res.xy_rms[6] for res in results], ".-",)
plt.xlabel("Training set size")
plt.ylabel("z rms. / µm")
plt.tight_layout()
plt.show()